Real-Time High-Resolution Background Matting阅读笔记
Abstract
我们介绍了一种, 实时的、高分辨的能够操作4K分辨30帧、HD分辨60帧的背景替代技术。我们技术基于Background matting。主要的挑战是计算高质量的alpha matte[1] $alpha$通道,用于描述图像中每个像素的透明度信息,用来将图像与背景分离开,创建一个平滑的边界。通过使用一个额外的带有灰度值的图像来表示透明度,较暗的像素表示较低的透明度。参考资料和前景层、保留部分头发细节。为了达到这个目标,我们采用了两层神经网络:基本的网络负责计算低分辩的结果,另一个网络负责对前者的细化。
Introduction
背景替代技术呗广泛用于视频相关的工具如Zoom. Google Meet 和 Microsoft Teams。
除了娱乐价值, 背景替代技术还能提高隐私,尤其是在视频中用户不想展示他的位置和环境给其他人的情况。这类视频相关的应用最大的挑战就是用户并不能如电影特效制作那般传统地能够有绿布或者其他物理媒介用来帮助背景替代的东西。
尽管很多工具提供背景替代的功能,但他们在边界上仍然有人工痕迹,特别是在一些有较好细节的头发、眼镜的地方。
相反的, 传统的图片替代方法如下述论文[6, 16, 17, 30, 9, 2, 7][2] 一些图片替代的方法,可以阅读。参考资料等提供足够高质量的结果,但并非实时和高分辨, 并且需要手工输入。在这篇文章中,我们将首次介绍一种全自动的, 实时的, 高分辨的替代技术, 能够在30帧4K分辨、60帧HD分辨下工作。我们的方法依赖于捕获一个额外的背景图去计算$\alpha$通道和前景层, 被称为背景替代的技术。
设计一个能达到实时、高分辨的人的视频的神经网络是巨大挑战,尤其是当头发部分的细微粒度细节重要时。此外,先前的最高基数的办法也被局限在8帧$512\times512$分辨。在如此高的分辨下训练一个深度网络是十分缓慢和占据内存的。它还需要大量高质量图像及其$\alpha$通道去生成。公开的可用的数据集也十分稀少。
由于收集人工校准过的大量数据集十分困难, 我们计划用一系列不同特征的数据集训练我们的神经网络。为此,我们引入了具有高分辨率 Alpha Matte 和前景层的 Video Matte240K 和 PhotoMatte13K/85,这些图像使用色度键技术[3] 未学习的技术。参考资料提取而来。我们首先在这些更大的带有人体姿势划分的$\alpha$通道数据集上训练神经网络学习鲁棒先验[4] 鲁棒先验指对图像或图像中的某些属性进行建模和预先假设,通过引入鲁棒先验,可以在图像处理任务中提供额外的信息和约束,从而改善算法的性能和鲁棒性。参考资料。然后再在公开可用的人工校验过的数据集上训练学习细微粒度的细节。
为了设计能够实时操纵高分辨图像的神经网络,我们观察到图像在相对少的地方需要细微粒度的细化。因此,我们介入基本的低分辩下能够预测$\alpha$通道和前景层的网络连带一个能分辨哪些部分需要高分辨细化的错误预测图。
Related Work
背景替代能够被分割或抠图。尽管二分割快而高效, 其结果包含明显的人工痕迹。$\alpha$通道能够产生视觉上令人满意的合成效果,但通常需要手动注释或已知背景图像。
Our Approach
给定一个图像$I$和捕获的背景$B$, 我们可以预测$\alpha$通道和前景F, 通过$I’=\alpha F+(1-\alpha)B’$
其中$B’$是新的背景。我们采用$F^R=F-I$
而非直接解决前景。然后通过将$F^R$添加到$I$, $F$用 $F=max(min(F^R+I, 1), 0)$
固定。
我们发现这个公式提升了学习过程,并且允许我们能够将低分辩的残留前景应用到高分辨输出图像,通过上采样[5] 上采样, 将图像分辨率增加或放大的过程。通过插值算法可以在已有的像素之间插入新的像素,从而增加图像的细节和清晰度。常见的上采样方法包括最近邻插值、双线性插值和卷积插值等。参考资料将低分辨率的前景残差应用到高分辨率的输入图像上,从而帮助了我们后面描述的架构。
正如图四所展示的,人类抠图通常非常稀疏,大部分的像素区域要么属于背景($ \alpha=0$)要么属于前景($\alpha=1$)并且只有一小部分区域包含(需要)细化细节, 例如在头发、眼镜和人的轮廓周围。因此,我们引入两个神经网络而非单一一个处理高分辨图像。一个操作低分辩另一个只操作在原分辨上选择的部分,基于对先前神经网络的预测。
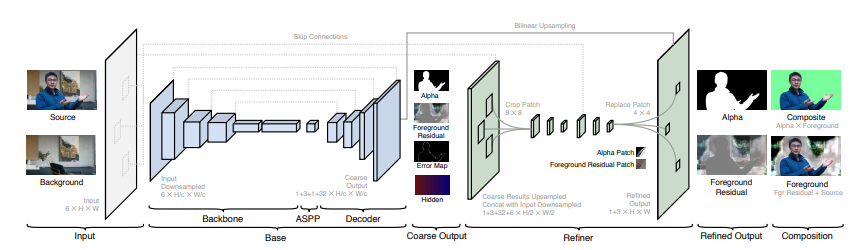
整体结构包含一个基本的神经网络$G_{base}$和一个细化神经网络$G_{refine}$给定一个原始的图像$I$和一个捕获的背景$B$, 我们先按照因子$c$进行下采样得到$I_c$和$B_c$。基本的神经网络$G_{base}$把$I_c$和$B_c$作为输入并预测$\alpha$通道的的粗粒度, 前景残留$F^R_c$, 一个误差预测图$E_c$,和隐藏特征$H_c$。然后细化的神经网络$G_{refine}$用$H_c$, $I$, 和$B$去在误差预测图$E_c$大的区域细化$\alpha_c$和$F^R_c$并且在原生成$\alpha$和前景残留$F^R$。我们的模型是完全卷积的并且经过训练可以适应任意尺寸和宽高比的图像。
Base Network
基础的的网络是基于DeepLavC3和DeepLavV3+结构的全卷积编码器-解码器,这些架构在2017和2018年在语义分割任务中取得了最先进的性能。我们的基础网络包含了三个处理:Backbone[6] Backbone参考资料, ASPP[7] ASPP参考资料, and Decoder[8] 解码器,用于还原输出图像的模块,接受从主干网络或编码器输出的低维特征表示。参考资料.我们采用ResNet-50作为我们的特征提取编码器,可以用ResNet-101和MobileNetV2去提高速度和质量。我们采用ASPP方法对上一步操作进行池化。ASPP模块由多个采用不同夸张率的空洞卷积滤波器组成,通常有3、6、9等不同扩张率。我们的解码器网络在每步采用双线性插值上采样,从backbone中把跳过的连接联系起来,用$3\times3$的convolution[9] convolution参考资料
。解码器网络输出粗粒度的$\alpha_c$,前景残留$F^R$, 误差预测图$E_c$和一个32通道的隐藏特征$H_c$。隐藏特征$H_c$包含了所有在细化网络中有用的文本。
Refinement Network
细化网络的目标是减少计算和恢复高分辨抠图细节。基础网络操作的是整个图像,而细化网络了指操作被误差预测图$E_c$选中的部分。我们进行了两阶段的细化处理, 首先在原始分辨率的1/2处, 然后在完全分辨率上进行。在推理过程中,我们对k个图块进行细化处理, 其中k可以事先设置, 也可以根据质量和计算时间之间的权衡阈值进行设置。
给定在原分辨率$\frac{1}{c}$上的粗粒度误差预测图$E_c$, 我们首先对其$\frac{1}{4}$原分辨率进行重采样得到$E_4$, 使得图上的每个像素对应原分辨率上的一个$4\times4$块。我们从$E_4$ 选取上方最高预测误差的k个像素去定位接下来将要被细化网络细化的k个$4\times4$块的位置。总的要被细化的原分辨率下像素是16k个。
我们定义了两阶段的细化过程。首先,我们粗粒度的输出进行双线性重采样,即$\alpha_c$, 前景残差$F^R_c$和隐藏特征$H_c$, 以及图像$I$和背景$B$,它们缩放到原分辨率$\frac{1}{2}$处,并将他们连接成特征。然后我们将选取到的错误位置的区域附近扩展到$8\times8$, 并令其通过两层无附加的$3\times3$的卷积。这些中间的特征又被$8\times8$的上采样然后被连接成特征,并与从原始分辨率输入图像$I$和背景$B$中提取的相应位置的$8\times8$补丁连接在一起。之后我们再将它应用到两层无附件的$3\times3$卷积上。最终,我们对粗粒度的$\alpha_c$和前景残差$F^R$进行原分辨率上采样,并把它和我们细化后的$4\times4$部分交换从而获得最终的$\alpha$和前景残差$F^R$.整个过程被描述在图三中。
Training
所又的抠图数据集都提供一个$\alpha$和一个前景层,我们将它们合成在一个高分辨率背景下。我们采用多种数据增强技术来避免过拟合, 并帮助模型适应具有挑战性的真实世界情况。我们对前景层和背景层分别独立地应用仿射变换、水平变化、亮度、色调、和饱和度调整、模糊、锐化、和随机噪声等数据增强方式。我们还对背景进行轻微平移以模拟错位,并创造人工阴影模拟真实环境下一个主体投射阴影的情况。我们在每个小批次中随机裁剪图像,使高度和宽度均匀分布在1024和2048之间,从而支持任何分辨率和纵横比的推理。
对于$\alpha$的真值$\alpha^ \star$,我们对整个$\alpha$及其Sobel[10] Sobel算子基于差分运算,结合了水平和垂直方向上的滤波器核。这两个核被分别称为Sobel X和Sobel Y。
通常其梯度幅度是:
gradient_magnitude = $sqrt{X^2+Y^2}$参考资料算子采用梯度下降的L1损失[11] L1损失,也称为平均绝对误差(MAE),计算了每个像素的预测值和真实值之间的差异并取其绝对值。然后将这些差异值求和并取平均,得到整个图像的损失值。参考资料进行学习:
$$
L_\alpha = \parallel\alpha-\alpha^ \star\parallel_1 + \parallel\nabla\alpha-\nabla\alpha^ \star\parallel_1
$$
通过$F=max(min(F^R + I, 1), 0)$,我们从前景残差$F^R$中获取前景层。我们仅在$\alpha^ \star$>0的像素上计算L1损失:
$$
L_F = \parallel(\alpha^ \star > 0) \times (F - F^ \star) )\parallel_1
$$
对于选择要细化的区域,我们定义真实误差映射$E^ \star = \mid \alpha - \alpha^ \star \mid $.之后我们计算预测误差图和真实误差图之间的均方误差作为损失函数:
$$
L_E=\parallel E-E^ \star\parallel_2
$$
这个损失函数会促使预测误差图在预测$\alpha$和真实误差$\alpha$之间存在较大的差异值。随着预测$\alpha$的提升,真是误差图会随着迭代而变化。随着时间推移,误差图会逐渐收敛并在如头发的复杂区域预测出高误差,如果仅进行上采样的话,会导致差的合成效果。
基础网络($\alpha_c,F^R_c, E_c, H_c)$ = $G_{base}$($I_c, B_c$)在原图像分辨率的$\frac{1}{c}$处操作,并用以下的损失函数训练:
$$
L_{base} = L_{\alpha_c} + L_{F_c} + L_{E_c}.
$$
我们使用在ImageNet和Pascal Voc 数据集预先训练了语义分割的DeepLavV3来初始化我们的模型的特征提取和金字塔池化方法。我们首先训练基础网络直到收敛,然后添加细化方法并联合训练。我们在训练中使用Adam优化器(c=4,k=5000)。对于只训练基础网络,我们采用批量大小为8和学习率【1e-4, 5e-4, 5e-4】来分别更新特征提取主干,ASPP模块和解码器。对于联合训练,我们采用批量大小为4和学习率【5e-5,5e-5,1e-4,3e-4】训练特征提取主干,ASPP,解码器和细化模块。
我们按照下面顺序在多重训练集上训练我们的模型。首先,我们只训练基础网络$G_{base}$然后将整个$G_{base}$和$G_{refine}$在Video Matte240K上训练,能让我们的模型适应不同的主题和姿势。接下来,我们在PhotoMatte13K上联合训练我们的模型以提高高分辨的细节。最终,我们在Distinction-646上联合训练我们的模型。数据集只含有362个独特的训练样本,但他们都是高质量的且包含了人工校准的前景,对于提升我们模型产出的前景质量有很高的提升。我们选择不在AIM数据集上训练而是指用它测试,是因为根据我们在第六节中的消融研究结果显示,它会导致质量下降。



